ゲノコン2021 問題Cの最高点解法
ゲノコンを頑張っていました。順位は5位で審査員特別賞を頂きました。
D問題については別途記事を書こうと思いますが、C問題で4人しかいない最高点を取れたので、解法を記しておきます。
問題
Largeで40個、長さ750の文字列をいい感じに合わせる(マルチプルアラインメント)という問題です。
サンプル1の入力、出力を見るとわかりやすいと思います。
解法の概略
- ACGTのいずれかを1文字ずつ決めていくことで参照文字列
を作るビームサーチを行う。
- 参照文字列を作成する途中の文字列
に対する評価をDPで行う(詳細は後述)
- 文字列
文字目の評価を行うとき、それまでのDP配列を用いて計算できるため、文字の追加ごとの計算量はO(文字列の個数 x 長さ)で済む。
これを概ねビーム幅 x 文字列の長さの回数行うため、O(ビーム幅 x 文字列の個数 x 長さ x 長さ)で計算できる - 計算時間およびメモリはかなりタイトであり、ビーム幅4までしか発射できなかった。ただし、後述の工夫を使うことで、10倍くらいにできそう。
以下、ビーム幅を、文字列の個数を
、文字列の長さを
、参照文字列の長さを
、文字列の長さを
とします。
ポイント1 - 参照文字列に対するスコア計算
まず、m本の文字列を一度に扱ってm対mにするより、1つ参照文字列を作って1対mにした方が効果的に思える。以下のようにすると、1対mの形で扱える。
参照文字列があるとき、
に各文字列をうまく対応させることによってできるマルチプルアラインメントのスコアは、
以下のようにDPで計算したと各文字列
のアラインメントのスコアの総和で計算できる。
を
文字目まで使ったときのコストを考える
]は、以下のうちもっとも小さいものとなる
(
(
- スコアは
となる
このDPを直感的に表すと以下のとおり:
例を挙げると、参照文字列がGAG、文字列
がGGAGCのとき、DPテーブルは以下のようになり、スコアは2となる。
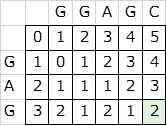
ここで、マルチプルアラインメントで複数の削除や挿入が重なることが気になるが、以下のとおり各文字列での削除・挿入コストの和で捉えて良さそうである。
複数の文字列で同じところを削除するときは、以下のようになる。
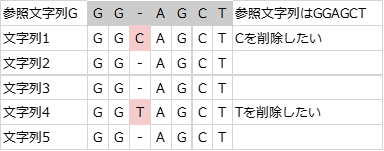
複数の文字列で同じところに挿入するときは、以下のようになる。
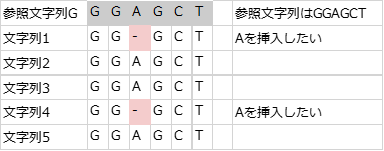
ポイント2 - 参照文字列の途中経過の評価
上記のスコアは、文字列の余った部分がコストになってしまい、参照文字列
を作成する途中の状態の評価としては適切でないため、ビームサーチの評価関数としては使えない。
ここで、ビームサーチの評価関数として適切な値を考える。
の最小値は、各文字列に対してそのあとに理想的に参照文字列に文字を加えていった場合のスコアといえ、評価関数として良さそうである。
例を挙げると、参照文字列がGAG、文字列
がGGAGCのとき、そのあとに理想的に参照文字列に文字を加えて得られるベストなスコアは1であり、下図のピンク部分の最小値である。
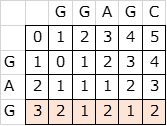
つまり、評価関数としては の最小値を使い、最終的な評価としては
を使うビームサーチとなる。
ポイント3 - ビームサーチでの効率的な計算
参照文字列と一つの文字列のアラインメントを求めるDPであっても、計算量はとなってしまう。
これを毎回フルで各文字列に対して行うと10秒ではとても足りない。
ビームサーチでは、参照文字列の途中の文字列までの評価が既にある状態で、
に1文字足した場合の評価を求めれば良い。
これは、ポイント2のDP配列のピンク色の部分だけを計算すれば良いため、各ビームサーチで1文字加える部分での計算量は
で済む。
これらが揃うことで、無事ビームサーチの枠組みに持ち込める。
参照文字列の長さはこの問題では大体各文字列の長さと同じくらいになるので、ビームサーチのステップも程度。計算量は
となり、なんとか計算可能になった。
さらなる計算量の改善
実は提供されたゲノコンD問題のスコアリングの関数がヒントになっている。 ゲノコンD問題は文字列の長さが30000もあり、素直に計算するとPCが爆発しそうでどうするんだ?と思った。コードをよく読んでみると、アラインメントを求めるときに文字列のずれを600程度に制限してスコア計算を行っている。
ある2つの文字列のアラインメントを完全に求める計算量はであるが、それらの2つの文字列の中のずれを幅
までしか許容しないとすれば、
まで減らすことができる。
ゲノコンCにこれを適用すると、B = L/20とすることで、計算量を1/10にでき、ビーム幅が増やせる。なお、試していません。。
他の方の解法
他の最高得点の解法は結構違うようで、なかなか面白いですね。
ゲノコン #genocon2021 お疲れさまでした。2 位でした。1 位の方のスコアは 1 段階上っぽいですね。お強い。C 問題は割と綺麗に出来たと思うので解法を共有します。運営の皆様、Oxford Nanopore Technologies 様、AtCoder 社様、参加者の皆様どうも有り難うございました。 pic.twitter.com/6YlGh2bFtO
— yuroyentan (@yuroyentan) 2021年9月29日
8/23 ~ 9/20 まで、「DNA 配列解析チャレンジ(ゲノコン 2021)」というコンテストに参加しました。
— square1001 @ 9/24 20 時アカウント運用開始! (@square10011) 2021年9月29日
DNA 解析の問題をプログラミングで解くコンテストでした。メイン問題(D 問題)では上手く行きませんでしたが、ところが C 問題で最高得点を取り入賞しました🙂#genocon2021 pic.twitter.com/MfwVbdI6L3