AtCoder Heuristic Contest 003 参加記
AtCoder Heuristic Contest 003に結構時間を溶かして参加し、96.7Bで暫定29位でした。
https://atcoder.jp/contests/ahc003
解法
- ベースはRidge回帰+ダイクストラで最短路を選択
- M=2を意識して行/列ごとに2個パラメータを持たせるようにした
- 最初の90ターンは探索、「いい感じ」に未探索のパスを選択
- 「いい感じ」のパスが見つからない場合は最短路を選択
- その後は最短路を選択しつづける
- あまり探索していない行/列は長さがちょっと短いように補正する
感想
早めに回帰の解法を思いつけて、土日に94Bまでには比較的良いペースで辿りつけた。 いろいろ分析を重ねたものの、上位との3Bの差を埋められるような大きさの知見が得られずにずっと苦しんでいた。 回帰に正則化を入れて更新頻度も多くしたところ96Bまで一気に上がり、そこから細かい工夫とパラメータチューニングで96.7B。
GCPのCloud RunでOptunaで自動パラメータチューニングする仕組みを立てていて、これはかなり便利。 20ケース x 100試行が1-2分で帰ってくるので、ちょっと迷ったときにパラメータ化して良さげなところに設定することができる。
プログラムはC#だけど、分析には結構Pythonを使っていて、地味にPythonのタスクランナーであるpython-invokeも便利でした。設定次第でカレントディレクトリに依存せずにいろんな処理をできるので、ターミナルがぐちゃぐちゃにならずにすむ。
フロントエンド何もわからない(その6)〜 Introduction To Heuristic Contestのビジュアライザを作った
threecourse.hatenablog.com のつづきです。
今回の成果物はAtCoderのIntroduction to Heuristics Contest のビジュアライズで、人間では到底良さげな解に到達できないところ、最適化だと1秒程度で綺麗な解を出してくれるのが見てて面白い。
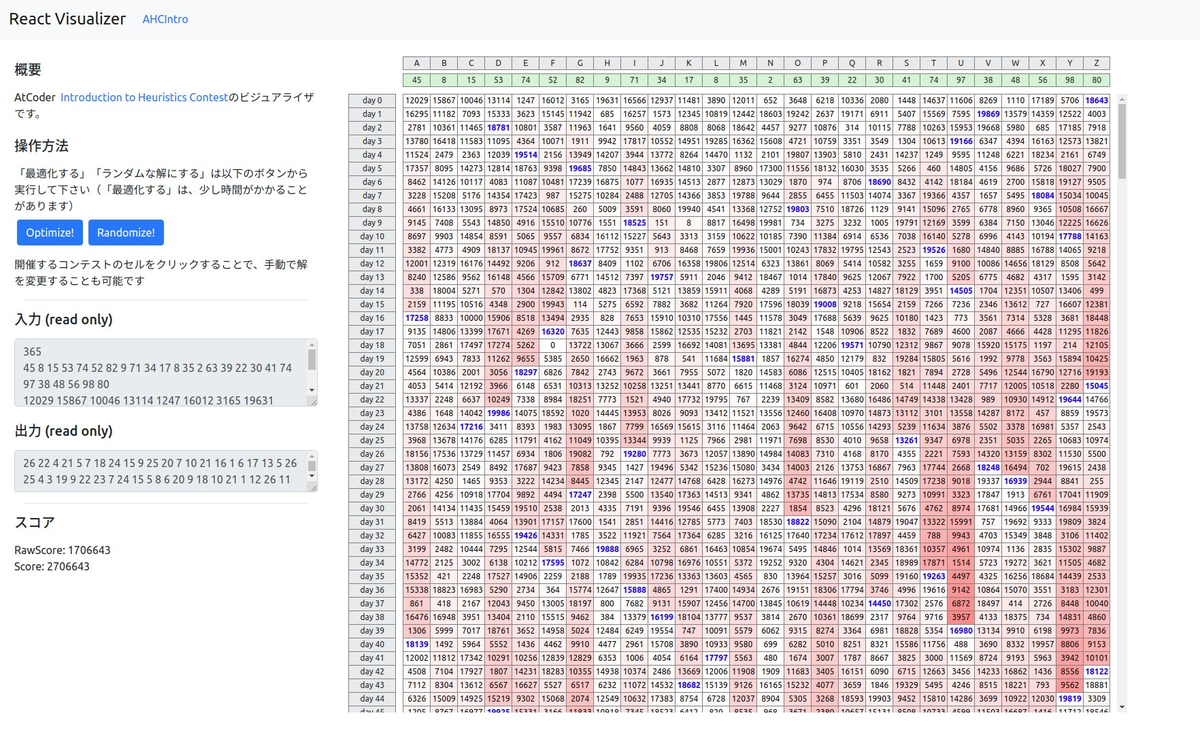
Reactによるフロントエンドの構築
- React + Reduxによる構成
- ReduxのStateの中に情報を全部詰め込むようにするのが一番分かりやすかった。useDispatchを使うとどこからでも処理を走らせられ、useSelectorを使うとどこからでも情報を取得できる
- 今回は26x365で10000個近い要素を扱うので、何も考えなしに扱うと再レンダリングが走って更新がかなり遅くなってしまうという難しさがあった
- 10000個の配列を毎回生成する程度のコストは問題ではなく、それらのコンポーネントを再レンダリングしようとするのが速度低下の原因
- react.Memo/useMemoを使うことで不要なコンポーネントの再レンダリングを抑えるとともに、各セルのコンポーネントからuseSelectorで値を取得させるようにした。useSelectorで取得した値が変わらない場合には再レンダリングが走らないため、十分な速度で動く
.NET Core(C#)によるバックエンドの構築
ローカルでのフロントエンド・バックエンド環境の構築
- フロントエンドからバックエンドのAPIを叩くことで計算結果を取得して表示する
- フロントエンドとバックエンドを分けると、バックエンドをC#などの好きな言語で書ける
- Docker化して、docker-composeで立ち上げるようにすればわりと楽にサーバを同時に立てられる
GCPのCloud Runでのフロントエンド・バックエンド環境の構築
- Cloud Runは、サーバとしてDockerイメージをデプロイすると、自動的によしなにしてくれるサービス。
- フロントエンド、バックエンドをそれぞれCloud Runのサービスとして公開
- フロントエンドはReactをビルドすると静的ファイルになるので、http-serverで起動させた
- バックエンドは非公開としてフロントエンドからのみ呼び出せるようにしたかったが、Reactから呼び出すことが上手く行かなかったので公開するようにした。
- この辺はもっとうまいやり方がありそう
- Cloud Runは、CPU/メモリは格安なのだが、以前ログ課金で死にかけたことがあるので恐る恐るやっている
- 良い機会なのでドメイン取ってみた
- .Net CoreはReadyToRun コンパイルをすることで起動が高速になった。そうしないと、Cloud Run環境では遅いかもしれない https://docs.microsoft.com/ja-jp/dotnet/core/deploying/ready-to-run
マラソンマッチのビジュアライザいろいろ
マラソンマッチのビジュアライザについて、各者/各社さまざまな作り方をしているので、まとめてみました。
longcontest-visualizer-framework
kimiyukiさんのlongcontest-visualizer-frameworkおよびRCO/リクルートの日本橋ハーフマラソンで使われている方法
(お互いに参考にしながら開発している?)
- 時系列ごとに行動を出力する形式の問題では、時系列に沿った状況の推移が見たい。そのため、UIで時系列に沿って再生・巻戻し・早送りする機能がある
- 入力・出力から毎フレームの情報を計算したのち、各フレームの情報をhtmlのCanvas 2Dに描画する
- Canvasを画像に変換したり、動画に変換する機能もある(https://github.com/jnordberg/gif.js を使っている)
画像出力からの動画変換
そういえばですが、標準エラー出力に
— kimiyuki@うさぎ🐇 (@kimiyuki_u) 2021年5月1日
-----BEGIN-----
LUDLUURLDDDDDDDLULDDDDD
-----END-----
みたいなフォーマットで暫定解を吐くようにして python3 https://t.co/9mJ3Szh8Si ってやればこの動画ができるようなスクリプトがあるので、まだ復習してる人はぜひ#AHC002https://t.co/g6VBDQ9Br7 https://t.co/iJzm3cDhoQ
https://github.com/kmyk/atcoder-heuristic-contest-002/blob/master/scripts/visualize.py
以下のようにして、AtCoder Heuristic Contest002の焼きなましの解の改善の様子を動画で出力している
- ----BEGIN----と----END----と囲まれた範囲はビジュアライザ用出力とする。解法プログラム内で一定間隔ごとにビジュアライザ用出力を行うようにしておく。
- 各ビジュアライザ用出力ごとに公式ビジュアライザを呼び出して画像を出力する
- 出力された画像をffmpegで動画に変換する
画像を出すだけなら、いろんなアプローチがある(Pythonのmatplotlib, RustのSVGクレートなど)。とりあえず画像を出力してffmpegで動画変換というのは汎用的なアプローチかもしれない。
gvc/General Visualizer Client
colunさんのマラソンマッチ用ビジュアライザのプロトコル/ライブラリ
解法プログラム内でプロトコルに沿った形式で命令を出力し、それを読み込んでJavaプログラムで表示する
siv3d
マラソンR3、今回も@ReputelessさんのSiv3Dをビジュアライザに使いました、感謝!手動配置したあとに、最小費用流で、選択したマスの中で最適な絵が自動で選ばれるようにしました。動画を作れる機能もあるっぽいので、あとで試します pic.twitter.com/wtlQDMkVV7
— nico_shindannin(診断人) (@nico_shindannin) 2014年7月11日
「ゲームとメディアアートのための C++ ライブラリ」であるsiv3dを用いて表示する
Unity
天下一 Game Battle Contest 2021 Spring で使われた方法
今回は 5 体のエージェントを操作して、タスクを達成するゲームです。
— 天下一プログラマーコンテスト (@klab_tenka1) 2021年4月24日
みなさんのご参加をお待ちしています!
※参加はコチラから!https://t.co/O093n0lOal#klabtenka1 pic.twitter.com/TLiRuBtTSj
https://github.com/KLab/tenka1-2021-spring
UnityのWebGLビルドを使っている。魅せる目的では有効そう。ビジュアライザで求められる要件とゲームエンジンの相性は良いように思えるが、さすがにヘビーな気はする
React
最近私が研究しているアプローチ
数理最適化 Advent Calendar 2020のネタがやっと完成した pic.twitter.com/AnawBv6Q1d
— threecourse (@threecourse) 2020年12月19日
ナーススケジューリング問題を焼きなまし法により解く
https://threecourse.github.io/nurse-scheduling-simulated-annealing/
ソフトウェアのアーキテクチャについて(その3)~ 良書とクリーンアーキテクチャ
以下の記事の続きです。 threecourse.hatenablog.com
ドメイン駆動設計についての書籍
ドメイン駆動設計周りを学ぶには、以下の2冊が良さそう。
「実践ドメイン駆動設計」から学ぶDDDの実装入門
www.amazon.co.jp/dp/B07S675HVM
amazonレビューを見るとスルーしてしまいそうになるが、用語や概念の定義をしっかり説明しようとしており、個人的にはこのテーマの本ではベスト。ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本
www.amazon.co.jp/dp/B082WXZVPC
有名な実践ドメイン駆動設計(www.amazon.co.jp/dp/B00UX9VJGW)を最初に読むと、主張が分かりづらかったり、概念の定義がはっきりとなされていないように思います。上記の書籍は、定義をできる限り明確に説明していたり、具体例で表現しているため比較的分かりやすいです。
クリーンアーキテクチャ

クリーンアーキテクチャという良さげな設計があるらしく、上の図で表されます。
こちらもClean Architecture 達人に学ぶソフトウェアの構造と設計(www.amazon.co.jp/dp/B07FSBHS2V) を読んでも良くわからない部分があり、「ドメイン駆動設計入門」の著者のQiitaおよびGithubが参考になりました。
実装クリーンアーキテクチャ
https://qiita.com/nrslib/items/a5f902c4defc83bd46b8上記Qiita記事に対応するC#プロジェクト
https://github.com/nrslib/CleanArchitectureドメイン駆動設計入門に対応するC#プロジェクト
https://github.com/nrslib/itddd
以下は私の理解です:
- 具体的なクラスでなく、インターフェイスに依存することによって、柔軟性やテスト容易性を増す
- 双方向に具体的なクラスに依存させると密結合になってしまう。だからといって双方向で抽象に依存させられるかというとそうではない。例えば、ユーザー作成処理をユーザーという具体的な概念なしに定義するのはむしろ不自然。
よって、具体的なクラスへの依存は片方向とし、逆はインターフェースへの依存としたい。Entities ← UseCases ← Controllers/Gateways/Presenters という方向への具体的なクラスへの依存は許容するが、逆方向は許容しない。
つまり、UseCasesはEntitiesを利用できるし、ControllersはUseCasesを利用できるが、EntitiesはUseCasesをインターフェースを通してのみ参照でき、UseCasesはControllersをインターフェースを通してのみ参照できる処理は、インターフェイスで定義されるUseCaseとその実装であるInteractorで定義される
- インターフェイスには、最終的に具体的なクラスを設定する必要がある(=依存オブジェクトを注入する必要がある)。各クラスのコンストラクタでいちいちセットする方法もあるが、この処理を行うためのDIコンテナと言われるライブラリがある。
ADOP
クリーンアーキテクチャを読んでいて、Entities, UseCasesとそれ以外を明確に分離することは有益であるが、小さなプロジェクトの初期段階から各インターフェイス・オブジェクトを作っていくのは非効率で煩雑ではないのかな。。
と思っていたら、上記の著者の方がADOPという実装パターンを考案されていて、納得感がありました。

私の理解では、以下のとおりです。
- ドメインレイヤー(Domain Layer)、アプリケーションレイヤー(Application Layer )、アザーズレイヤー(Others Layer)に分ける。
- Domain Layerには、ソフトウェアを適用しようとする対象領域(ドメイン)の事物を直接的に表現するコード、もしくは表現を支援するコードを記述する
- Application Layerには、ドメインの事物を表現するコードを取り扱い、ソフトウェアで成し遂げたいユースケースを達成するコードを記述する
- Others Layerには、アプリケーションレイヤーとドメインレイヤー以外のもの、例えばユーザーインターフェイスやデータベースに関するコードなどを記述する
- Domain LayerのオブジェクトがApplication Layerに利用される、Domain Layer, Application LayerのオブジェクトがOthers Layerに利用されるのは問題ない。逆の場合は具体的なクラスを使用してはダメで、インターフェイスなどを通して汎化して利用する。
AtCoder Heuristic Contest 002 参加記
スコア4.32M 107位 パフォ2117でした。
解法
- mmlang (https://github.com/colun/mmlang) を使ってビームサーチ
- 点数は見ない
- 36分割して一筆書きのルートを設定し、できるだけ進みが遅い方を加点、ルートからはみ出たら減点
- 評価がタイのものは乱数を入れてランダムに評価
dfsの方が良かった説とか、焼きなましをしないと最上位は厳しいという話はありますが、ビームサーチにベットする戦略をとったのである程度しょうがないですね。
mmlang
mmlangを改造して以下のような機能を追加して使いました。結局使ったのは標準エラー出力機能のみでしたが。
mmlang無しにはこのスコアは出せていないと思うので神です。 一方で、入力をバグらせて最初の1時間溶かしたので、もう少し慣れたり、デバッグ用機能を拡充したほうが良さそうですね。
Cloud Run
Cloud Runに投げて並列でパラメータチューニングを試みましたが、
- そもそも変えるパラメータが無かった
- 結果が安定しない、確率的にエラーが発生するなどの複数の問題が発生した
という点で、結局使用することは無く。
colunさんのMM Languageを学ぶ
colunさんの作成されたMM Languageを学んでみます。
https://github.com/colun/mmlang
https://github.com/colun/mmlang/blob/master/doc/introduction.md
マラソンマッチに勝とう!という目的というよりは、DSLや抽象化を考察することで何かに役立てられないかという視点で学んでいます。 ただ、革新的なアプローチであり、実力以上の上振れが出るかもしれないので、興味のある方はぜひ実戦に使ってみると良いのではないでしょうか。
試験的にnotionでも公開してみました。
https://www.notion.so/colun-MM-Language-01a3c5bf337149889888df0c947bb7f6
以下、私の理解なので誤りがある部分も含まれるかもしれません、ご注意下さい。
MM Languageの概要
いわゆるDSLで、独自形式の言語でコードを記述すると、C++コードに変換し実行することができます。
(注:ここではDSLとしていますが、私がそう解釈しただけであり、その呼び方が適切でない可能性はあります)
目玉機能として、ループ演算子とビームサーチがあります。
特にビームサーチについて、通常はロジックの本質でない状態管理のコードを書く必要がありますが、MM Languageのビームサーチでは状態管理を自動的に効率的に行ってくれるため、本質部分に集中できます。 https://github.com/colun/mmlang/blob/master/doc/introduction.md#ビームサーチ
入力例は以下です。
https://github.com/colun/mmlang/blob/master/examples/chokudai005a.m2
出力例は以下です。
https://github.com/colun/mmlang/blob/develop/examples_outputs/chokudai005a.cpp
出力は元の入力コード(これはコンパイルされない)+ライブラリコード+変換後コード で構成されます。
DSL
DSLの文法は、PythonとC++が混じっている感じです。
PythonのLarkというDSLのパーサが使われています。
https://github.com/lark-parser/lark
動かすときの流れは、
- MM Languageの文法に沿ったコードを書き、拡張子.m2で保存する
- コマンドラインからDSLのパーサを起動し、変換を行うと、C++に変換されたコードが出力される(—runオプションをつけると、自動的にコードが実行される)
- コンテストには、変換されたC++コードを提出できる。
(https://github.com/colun/mmlang#readmeを参照)
ここで、変換後のファイルは以下で構成されます。
ループ演算子
本家の説明は以下にあります。
https://github.com/colun/mmlang/blob/develop/doc/introduction.md#ループ演算子
「ある文中にループ演算子が出てきた場合、文の外側にループを作成し、ループ演算子の箇所をループ変数で置き換える」と理解するのが分かりやすいと思います。
なので、被代入側でも代入側でも利用することができます。
// 被代入側にループ演算子を適用する例 - 入力コード A[0:3] = inputInt()
// 被代入側にループ演算子を適用する例 - 変換後C++コード for(int $1=0; $1<3; ++$1) A[$1] = inputInt();
// 代入側などにループ演算子を適用する例 - 入力コード print(0:3)
// 代入側などにループ演算子を適用する例 - 変換後C++コード for(int $1=0; $1<3; ++$1) print($1);
(実際のコード変換とは異なります)
なお、
- 文中にn個のループ演算子を使用した場合、n重ループとなります。
- ループ変数をバインドし、文の他の箇所で使用することができます。
ビームサーチ
本家の説明はこちらになります。
https://github.com/colun/mmlang/blob/develop/doc/introduction.md#ビームサーチ
使い方は以下のようになります。
- ビームサーチのメインとなるロジックの関数に、@beamのようなデコレータをつける
(以下、更新関数ということにします) - 更新関数は、引数としてスコア・ハッシュ・操作などの情報をとる
- 更新関数は、ある状態から開始し、操作を行い次の世代の状態に更新したのちに、更新関数を再帰することで次の世代の状態の作成を行う
- 更新関数内で状態を管理する変数は、xarray, xvectorなどのメモリ自動管理型のデータ構造を利用する
通常はビームサーチを行う場合、状態の巻き戻し処理を行うか、盤面全体をコピーするかという処理が必要になります。MM Languageでは、ビームサーチクラスの機能およびメモリ自動管理型のデータ構造によって、自動で状態の巻き戻し処理が行われます。
ビームサーチの深み
では、上記のような挙動はどのような仕組みで実現されているのでしょうか?
ビームサーチの流れ
- ビームサーチのノード(xbeam$node)は、状態およびスコア、親ノードなどの情報を持ちます。
- ビームサーチクラス(xbeam)は、current_ranking, next_rankingという2つの変数を持ちます。これらは両端プライオリティキューであり、スコアとノードへのポインタを要素とします。
- 最初はcurrent_rankingに初期状態のノードをセットします。
以下を繰り返すことで、ビームサーチを行うことができます。
- current_rankingのスコアの最も大きいノードを処理します。
- 処理対象のノードの状態に対して、更新関数が実行されます。 更新関数の中で再帰で更新関数が呼び出されたときに、next_rankingに次の状態のノードを追加します。 ただし、ビーム幅を超える数のノードがnext_rankingに存在する場合、スコアの最も小さいノードは除外されます。
- 1-2を繰り返します。 current_rankingが空になるか、時間が経過した場合は次の世代のノードの実行に移ります。 次の世代の実行は、current_rankingにnext_rankingをコピーし、next_rankingを空にすることで行います。
状態の自動管理の実現
上記を単純に行うと、状態がめちゃくちゃになってしまいます。自動的な状態の巻き戻しをどう実現しているかを以下で説明します。
- xarray, xvectorなどのメモリ自動管理型のデータ構造は、その値が変更されるときに、変更点を記録する仕組みを持っている。
つまり、変更されるときに「変更箇所のポインタ、値のサイズ、変更前の値」を記録する。
(xmemクラスの静的変数であるbufferに記録領域を確保している) - 更新関数は、更新の最初から最後までの操作履歴をpatchとして保存する。
つまり、メモリ自動管理型のデータ構造による変更をウォッチし、「変更箇所のポインタ、値のサイズ、変更前の値、変更後の値」のリストを保存する。
(データ構造による変更のウォッチは、実際にはxmem::bufferの使用領域の増加分のみをみている) - patchの情報があれば、更新前の状態からredoして更新後の状態にすることも、更新後の状態からundoして更新前の状態にすることもできる。
- ビームサーチのノードは、「世代(depth)、親ノードのポインタ、patchのポインタ」の情報を持つ
- ビームサーチでは、ノードAを計算した後に別のノードBの計算を行うことになる。 このとき、状態をノードBの時点に変更してから計算する必要がある。
- ノードAからノードBの状態への変更は、ノードAとノードBの共通の先祖であるノードCを見つけ、ノードAからノードCまでのpatchをundoしていき、ノードCからノードBまでのpatchをredoしていくことで実現できる。(以下はイメージ図)

ソフトウェアのアーキテクチャについて(その2)~ ドメイン駆動設計から得られる知見
以下の記事の続きです。
参考文献
以下の本でドメイン駆動設計について学んだところ、小〜中規模のプログラムの設計・記述についてもなかなかの知見・示唆が得られたので、まとめてみます。
エリック・エヴァンスのドメイン駆動設計
https://www.amazon.co.jp/dp/B00GRKD6XUドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本
https://www.amazon.co.jp/dp/B082WXZVPC
以下も良い本らしいですが、まだ読んでないです
Patterns of Enterprise Application Architecture
https://www.amazon.co.jp/dp/B008OHVDFM
ドメイン駆動設計とは何か?
そもそもドメイン駆動設計とは何か?ということなのですが、私の理解では以下です。
- ソフトウェアを開発する対象となる領域の知識に焦点を当てた設計方法
ドメインの概念や事象を理解し、その中から問題解決に役立つものを抽出して得られた知識をソフトウェアに反映する。 - ドメインとは、ソフトウェアの対象とする知識、影響、または活動の領域
- 例えば会計システムであれば、金銭や帳票といった概念、その関係性や操作を適切にモデリングして設計する
ソフトウェアの対象とする領域を理解してモデリングしなきゃいけないのは当たり前だと思うので、これだけであればそれはそう、という感じ。
以下、「ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本 」をもとに具体的なパターンをまとめてみます。筆者の勝手な解釈が入っているため、元の書籍と記述が同じとは限りません。
概要
「ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本 」では、ドメイン駆動設計のパターンが以下に分けられています。
知識を表現するパターン
- 値オブジェクト
- エンティティ
- ドメインサービス
アプリケーションを実現するためのパターン
- リポジトリ
- アプリケーションサービス
- ファクトリ
知識を表現する、より発展的なパターン
- 集約
- 仕様
1. 知識を表現するパターン
1.1 値オブジェクト
「値」をクラスや構造体とするなどしてオブジェクトとして定義したもの
例
- 氏名を表すクラス(姓、名をフィールドとして持つ)
- 通貨を表すクラス(量、種類をフィールドとして持つ)
性質
- 不変である・交換が可能である
値を変えたい場合には代入によって変更する、それ自身の値が変わることはない - 等価性によって比較される
姓と名が同じであれば同じものであるとする、通貨の量と種類が同じであれば同じものとする
メリット
- 表現力を増す
値オブジェクトのクラスの定義のコード自体によって、氏名は姓と名から構成されるということが示される。 - 不正な値を存在させない
コンストラクタで判定するなどして不正な値を除外できる - 誤った代入を防ぐ
ユーザIDに商品IDを代入するようなことをできなくする - ロジックの散在を防ぐ
値オブジェクトに関連する処理をそのクラスにまとめて記述することができる
感想
上手く使うと便利。つい文字列で素朴に持ちがちな値も、構造体やクラスにまとめると見通しが良くなることがある。
1.2 エンティティ
同一性によって識別されるオブジェクト
例
- ユーザ(姓、名、ユーザID、ユーザ種別などのフィールドを持つ)
性質
- 可変である
再代入ではなく自身のフィールドの値を変えることで、ユーザ名などを変更できる - 同じ属性であっても区別される
姓や名といった属性が同じだけでは同一であるとは言えない。ユーザIDのような識別子で同一性を表す - 同一性を持つ
ユーザ名などを変更したとしても同一のユーザとして認識される
メリット
- コードのドキュメント性が高まる・ドメインにおける変更をコードに伝えやすくなる
エンティティに関連するルールはそのクラスにまとめて記述することができる
感想
- エンティティは値オブジェクトとの対比で理解するのがよさそう。
- 値オブジェクトはクラス化するのは自然ではない(氏名は文字列として持ってしまうことはありそう)なのだが、エンティティはクラス化するのは自然なので、これらのメリットはオブジェクト指向のメリットといえる
- エンティティはライフサイクルを持つというのは大きな特徴といえる
1.3 ドメインサービス
値オブジェクトやエンティティに関連するが、値オブジェクトやエンティティに記述すると不自然なふるまいを定義するクラス
例
ユーザの重複を確認するメソッドはユーザクラス自体に定義するとちょっと変。 UserServiceクラスを定義し、そこにExistsメソッドで確認するようにすると自然になる
感想
値オブジェクトやエンティティに記述すると不自然なメソッドをどう書こう・・と悩んだことがあるのでなるほどという感じ。名前もManagerとかUtilとかで悩んでいたが、Serviceを使えば良さそう。
2. アプリケーションを実現するためのパターン
2.1 リポジトリ
データの永続化と再構築の処理を抽象的に扱うためのオブジェクト
例およびメリット
アプリケーションを作る上では、ユーザの生成・変更といった処理をデータベースなどに反映し、「永続化」する必要がある。また、永続化されたデータから、ユーザーIDで検索するなどしたユーザをオブジェクトとして「再構築」する必要がある。
ここで、直接ユーザからデータベースを叩くコードを書いてしまうと、具体的なデータベースの操作を記述することになり、分かりづらく密結合なコードとなってしまう。 そこで、ユーザはIUserRepositoryインターフェイスに対して操作を行い、データベースとの接続等の処理はIUserRepositoryを実装したUserRepositoryクラスで行うことにする こうすることで、テストも行いやすくなる。リポジトリの実装をテスト用のものに差し替えることで、いちいちデータベースをセットアップする必要が無くなる。
感想
これもなるほど。知らないと直接データベースを叩いてしまうことがありそう。リポジトリだけでなく、一歩抽象化する思考を身に着けておくと応用が効きそう
2.2 アプリケーションサービス
ユースケースを実現するオブジェクト
例
ユーザの登録処理、ユーザ情報取得処理、ユーザ情報更新処理、退会処理といった処理を記述するクラス
論点
- アプリケーションサービスはあくまでドメインオブジェクトのタスク調整に徹するべきであり、ドメインのルールを記述すべきでない
データ転送用オブジェクト
ドメインオブジェクトを公開するかどうかという論点がある。コマンドオブジェクト
更新処理を定義するときに、ユーザ名だけを変更したいときもあれば、メールアドレスだけを変更したいこともある。このとき、引数で制御する方法もあるが、追加のたびにメソッドの引数が変わってしまう。この対処法として、コマンドオブジェクトを定義し、更新処理の引数としてコマンドオブジェクトを渡すという方法がある。
2.3 ファクトリ
生成を責務とするオブジェクトのこと
例
採番処理機能を実装したユーザ生成を行うため、IUserFactoryインターフェイスを実装したUserFactoryクラスを用いる
3. 知識を表現する、より発展的なパターン
3.1 集約
データを変更するための単位として扱われるオブジェクトの集まり
例
自動車とその要素である車輪・位置・タイヤがある場合に、自動車オブジェクトおよびそのフィールドとなる車輪・位置・タイヤのオブジェクトを定義する。 外部からは直接に車輪・位置・タイヤを参照せず、自動車オブジェクトに定義したメソッド経由で扱うようにする。このときの自動車オブジェクトを集約ルートという。
3.2 仕様
オブジェクトの評価を行うオブジェクト
オブジェクトの評価は単純なものであればメソッドとして定義すればよい。しかし、複雑な評価を仕様オブジェクトとすることで、評価のルールを切り出すことができる。 例えば、CircleFullSpecificationというクラスにサークルが満員かどうかという判定を定義し、それをアプリケーションサービスで呼び出すような方法がある また、仕様オブジェクトに対するAND/OR演算を定義するようなこともできる。
感想
- Strategyパターンに似ているように思えた。評価・戦略といった抽象的な概念をオブジェクトとすることで見通しが良くなることがある。
その他
CQS/CQRS(コマンドクエリ分離原則、コマンドクエリ責務分離原則)
状態を変更するメソッドとそうでない単に問い合わせをするメソッドを区別すると良い。