monaco editorにANTLRで独自言語を載せるをReactでやる
頑張った
以下の記事で、monaco editorにANTLRベースのパーサを組み込んで独自言語のシンタックスハイライトやエラー表示を行っている
これに、Reactからmonaco editorを使えるようにするやつを組み込む
すると簡単にReactに独自言語が動くエディタが載って遊べるぜ!というわけではなく、以下のようなことをやって解決
- @monaco-editor/reactで言語の登録をどこで行うか?
- EditorのbeforeMountとonMountで処理すれば良い
- Common JSとES moduleが混在していてimportやテストが上手く動かない
- ANTLRのバージョンを上げる
- テストもvitestに変更する
.NETのWebAssemblyをReactで動かそうとした
「WebブラウザやNode.jsなどのJavaScript/WebAssemblyランタイム上でJavaScriptから容易にC#などで書かれた.NETを呼び出して実行可能に」なったということなので、Reactから使えないか試してみました。
結果、
- dev環境(yarn dev)では動いた
- production環境(yarn buildしてごにょごにょ)では動かせなかった
フロントエンドの環境構築力が足りない・・ 結局はデータをどう受け渡すかが問題になりそうなので、もうちょっと複雑な例を試してみたかったのですが、一旦はこんな感じですね。
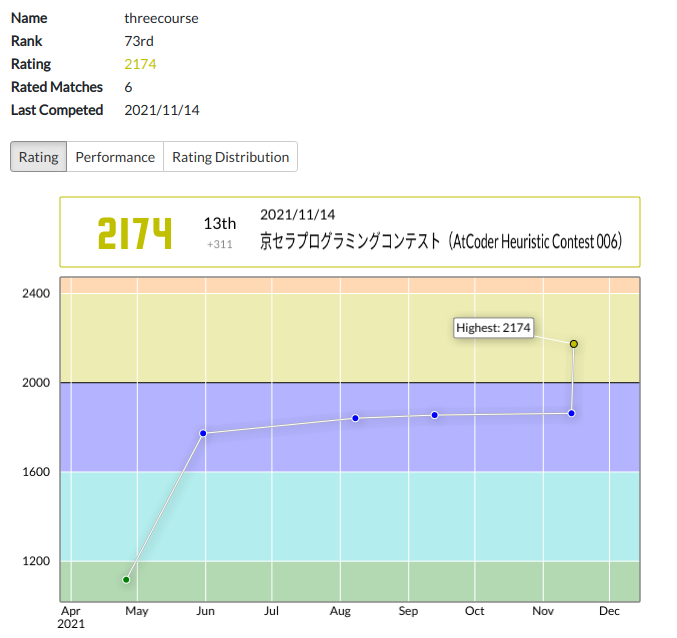
京セラプログラミングコンテスト(AtCoder Heuristic Contest 006)参戦記
AtCoder Heuristic Contest 006に参加して、13位 performance 2831、人生初の赤パフォでした。
レーティングも2174と黄色入りして、ランキングは73位でなかなかの順位です。
自社の応募要件に「ヒューリスティック最適化に強いこと(threecourseと同レベル以上、平均してAHC100位程度を目安)」とか書いているので良い成績をとらなきゃ、でも精進する時間ないしみんな強いしどうすんだ、と思っていましたが一発当てることができてほっとしています。
考察
開始5分での考察はこんな感じ。
- 変なTSP(巡回セールスマン問題)っぽい
- ぱっと見、注文を取り替えて焼きなましするしかなさそう
- 入れ替えるときにベストなところに挿入すれば大体良さそう
- 理想的な解は pick1 -> pick2 -> pick3 -> deli2 -> pick4 -> deli3 -> deli1 -> deli4 のように、多少入り乱れつつも前半にpick多め、後半にdeli多めになりそう。
ほぼベストな考察ができていましたが、これくらいみんな考えてくるだろう、wataさんがwriterだからもう一工夫必要かとか思って1時間くらい考察しました。 「ルートを決め打ちしてその回りの注文を取っていく」みたいな解を考えるも、元の案の方がましそうだったので却下し、おとなしく実装。
わりと軽めの実装ながら、なんだかんだマラソンの実装はバグり散らかすため、2時間半経過時に実装を終えて投げると1.99Mでなんと4位!
以下のような改善案が思いついたのですが、結局高速化をバグらせて何もできず、ダメ元で温度変えていくつか投げて1時間半改善せず終了。
- 高速化
- TSPで有効とされているキックを導入する
- 入れ替えるときにベストなところに挿入するを真面目にやる
- 注文を取り替えずに順序を変える
解法
焼きなましで、近傍はランダムに注文を削除し、ランダムに注文を追加。このとき、「ベストな」ところに挿入する。
「ベストな」ところに挿入は、
- ルートの間のいずれかに最も短くなるようにpickを挿入(選択肢は注文の数 x 2)
- そのあとpickの後という制限のもとで同様にdeliを挿入
まぁまぁ賢い解が出ているように思います。
#AHC006 アニメーションできた pic.twitter.com/154aakCUkt
— threecourse (@threecourse) 2021年11月14日
解法の反省点
- あとから議論して気づいたのですが、pickとdeliでそれぞれ各地点に入れたときの距離のゲインを保持しておき、累積Maxのような構造を使うと計算量がO(注文)のままに真に「ベストな」挿入ができますね。
- 焼きなましの遷移時に無駄に配列をコピーしているのですが、グローバル領域に配列を保持しておいてそこに入れればオブジェクト生成コストを減らせそう。
ゲノコン 問題Dでやったこと
ゲノコンD問題でやったことです。途中暫定1位まで行ったのですが、そこから伸ばせませんでした。(D問題は6位)
分析用コードを消さずに提出したところを評価してもらったようで、審査員特別賞を頂くことができました。
問題の概要
- 文字A, C, G, Tからなる2本の秘密文字列sが存在する
- 2本の秘密文字列に対して観測や操作を行った結果である観測文字列が複数与えられる
- 文字列の長さは30,000〜100,000とかなり長い
- 観測文字列は、参照文字列Gとその差分を表す圧縮表現により与えられる
- 観測文字列をもとに、2本の秘密文字列を復元せよ
この問題の特徴としては、
- 通常のヒューリスティックコンテストでは、解に対応するスコアを手元で計算することが可能である。(AHC003のように不明な場合もあるが、秘密パラメータの生成方法が開示されている)
一方、今回は秘密文字列が分からないのでスコアは計算不能であり、不明なデータを推測するKaggleに近い形式の問題と言える。 - サンプルデータ数が9個と少なく、またサンプルデータと評価用のデータの性質が違うのは難しい点である。
解法
解0 - 自明解
参照文字列Gをそのまま出す → 9328点
解1 - 単純な多数決
- 観測文字列が2本あることは無視して1本だと思って、とりあえず多数決で直せばいいんじゃね?
- 挿入・削除を処理するのは面倒くさそう。不一致のみ多数決で修正する。
この方針で9790点
解法2 - 焼きなましによる観測文字列のグルーピング
問題のポイントは、それぞれの観測文字列を2つの秘密文字列のどちらかに対応するか定めることだと思いました。 粗い議論ですが、以下のように考えました。
- 観測文字列を2つの集合に分ける問題である。観測文字列の数は50-100程度と考えると、時間も十分にあるので、評価関数を定めて焼きなましで良さそう。
- ある文字にエラーが発生する確率をpとする。
観測文字列を2つに分けたとき、尤度はそれぞれの秘密文字列との差異をxとしたとき、概ねpxとなる。
尤度を最大化することを考えると、xを最小にすれば良い。 - 真の秘密文字列がわからないので、観測文字列を2つに分けたときのそれぞれの集合で、同じ位置で最大となる文字以外の総数をxとした。
これで10458点。
苦難のとき
あとは欠損・挿入を考慮してスコアを伸ばしていくだけです。まずは以下のような分析をしました。
- IGV Viewerを使って眺める
- 参照文字列, 出力解, 秘密文字列のアラインメントを合わせて出力する (これがかなり面倒くさい・・・)
そこで分かったこととしては、
- 不一致・欠損・挿入という3種類の観測エラーがあるが、不一致に関しては確かなものは直せば良い(一部は怪しい)が、2文字以上の欠損・挿入についてはかなり信用ならない。
- IGV Viewerで見て、明らかに直すべきとしか思えない欠損・挿入エラーについて、直すと不正解で減点になってしまうものがある。 全てが不正解ではなく、直すのが正解のものも20%-30%ある。長さが20とか50とかの挿入・欠損があり、正しく直せると大幅な点数増が期待できる。
各サンプルデータの満点からの差異がどこから来ているのかを把握することができた。その結果は以下である。

じゃあこれらを直せば良い点数が出る・・かというとそうではなく、これらを直そうとすると不正解になる欠損・挿入も拾ってしまう。
- 「多数決で普通に考えたら直すべき」文字列の前後を、直すと正解/不正解になるフラグを付けながら参照文字列、出力解、秘密文字列を出力したが、高い確率で正解である欠損・挿入を求める方法は分からず。
- 一点だけ有用な知見があり、挿入すべき文字列を繰り返すときは不正解である確率が高かった。これはサンプルデータでも評価データでも同じ傾向が見られた。
- タンデムリピート・イントロンなどバイオインフォマティクスのドメイン知識を得ようとしたが、スコアの改善に有用な知見は得られず。
最終提出の解法
分析の結果、解法2に加えて以下の方針を取り、10466点のものを提出しました。
- 挿入は1文字は常に採用、挿入すべき文字列を繰り返すときは不採用、そうでない場合は50文字以下を採用する
- 削除は1文字は常に採用、2文字以降の削除は不採用
ゲノコン2021 問題Cの最高点解法
ゲノコンを頑張っていました。順位は5位で審査員特別賞を頂きました。
D問題については別途記事を書こうと思いますが、C問題で4人しかいない最高点を取れたので、解法を記しておきます。
問題
Largeで40個、長さ750の文字列をいい感じに合わせる(マルチプルアラインメント)という問題です。
サンプル1の入力、出力を見るとわかりやすいと思います。
解法の概略
- ACGTのいずれかを1文字ずつ決めていくことで参照文字列
を作るビームサーチを行う。
- 参照文字列を作成する途中の文字列
に対する評価をDPで行う(詳細は後述)
- 文字列
文字目の評価を行うとき、それまでのDP配列を用いて計算できるため、文字の追加ごとの計算量はO(文字列の個数 x 長さ)で済む。
これを概ねビーム幅 x 文字列の長さの回数行うため、O(ビーム幅 x 文字列の個数 x 長さ x 長さ)で計算できる - 計算時間およびメモリはかなりタイトであり、ビーム幅4までしか発射できなかった。ただし、後述の工夫を使うことで、10倍くらいにできそう。
以下、ビーム幅を、文字列の個数を
、文字列の長さを
、参照文字列の長さを
、文字列の長さを
とします。
ポイント1 - 参照文字列に対するスコア計算
まず、m本の文字列を一度に扱ってm対mにするより、1つ参照文字列を作って1対mにした方が効果的に思える。以下のようにすると、1対mの形で扱える。
参照文字列があるとき、
に各文字列をうまく対応させることによってできるマルチプルアラインメントのスコアは、
以下のようにDPで計算したと各文字列
のアラインメントのスコアの総和で計算できる。
を
文字目まで使ったときのコストを考える
]は、以下のうちもっとも小さいものとなる
(
(
- スコアは
となる
このDPを直感的に表すと以下のとおり:
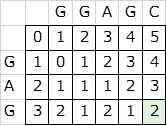
例を挙げると、参照文字列がGAG、文字列
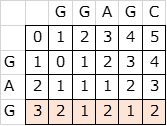
がGGAGCのとき、DPテーブルは以下のようになり、スコアは2となる。
ここで、マルチプルアラインメントで複数の削除や挿入が重なることが気になるが、以下のとおり各文字列での削除・挿入コストの和で捉えて良さそうである。
複数の文字列で同じところを削除するときは、以下のようになる。
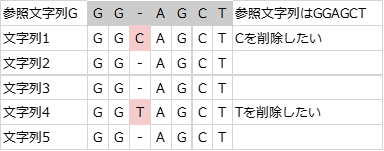
複数の文字列で同じところに挿入するときは、以下のようになる。
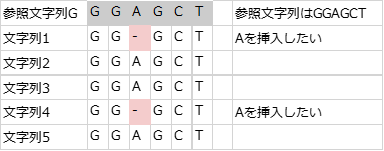
ポイント2 - 参照文字列の途中経過の評価
上記のスコアは、文字列の余った部分がコストになってしまい、参照文字列
を作成する途中の状態の評価としては適切でないため、ビームサーチの評価関数としては使えない。
ここで、ビームサーチの評価関数として適切な値を考える。
の最小値は、各文字列に対してそのあとに理想的に参照文字列に文字を加えていった場合のスコアといえ、評価関数として良さそうである。
例を挙げると、参照文字列がGAG、文字列
がGGAGCのとき、そのあとに理想的に参照文字列に文字を加えて得られるベストなスコアは1であり、下図のピンク部分の最小値である。
つまり、評価関数としては の最小値を使い、最終的な評価としては
を使うビームサーチとなる。
ポイント3 - ビームサーチでの効率的な計算
参照文字列と一つの文字列のアラインメントを求めるDPであっても、計算量はとなってしまう。
これを毎回フルで各文字列に対して行うと10秒ではとても足りない。
ビームサーチでは、参照文字列の途中の文字列までの評価が既にある状態で、
に1文字足した場合の評価を求めれば良い。
これは、ポイント2のDP配列のピンク色の部分だけを計算すれば良いため、各ビームサーチで1文字加える部分での計算量は
で済む。
これらが揃うことで、無事ビームサーチの枠組みに持ち込める。
参照文字列の長さはこの問題では大体各文字列の長さと同じくらいになるので、ビームサーチのステップも程度。計算量は
となり、なんとか計算可能になった。
さらなる計算量の改善
実は提供されたゲノコンD問題のスコアリングの関数がヒントになっている。 ゲノコンD問題は文字列の長さが30000もあり、素直に計算するとPCが爆発しそうでどうするんだ?と思った。コードをよく読んでみると、アラインメントを求めるときに文字列のずれを600程度に制限してスコア計算を行っている。
ある2つの文字列のアラインメントを完全に求める計算量はであるが、それらの2つの文字列の中のずれを幅
までしか許容しないとすれば、
まで減らすことができる。
ゲノコンCにこれを適用すると、B = L/20とすることで、計算量を1/10にでき、ビーム幅が増やせる。なお、試していません。。
他の方の解法
他の最高得点の解法は結構違うようで、なかなか面白いですね。
ゲノコン #genocon2021 お疲れさまでした。2 位でした。1 位の方のスコアは 1 段階上っぽいですね。お強い。C 問題は割と綺麗に出来たと思うので解法を共有します。運営の皆様、Oxford Nanopore Technologies 様、AtCoder 社様、参加者の皆様どうも有り難うございました。 pic.twitter.com/6YlGh2bFtO
— yuroyentan (@yuroyentan) 2021年9月29日
8/23 ~ 9/20 まで、「DNA 配列解析チャレンジ(ゲノコン 2021)」というコンテストに参加しました。
— square1001 @ 9/24 20 時アカウント運用開始! (@square10011) 2021年9月29日
DNA 解析の問題をプログラミングで解くコンテストでした。メイン問題(D 問題)では上手く行きませんでしたが、ところが C 問題で最高得点を取り入賞しました🙂#genocon2021 pic.twitter.com/MfwVbdI6L3
AtCoder Heuristic Contest 005 参加記
AtCoder Heuristic Contest 005に参加し、16.3Mで143位でした。
解法
本番では一番近くのまだ到達していない「通り」に進むだけの貪欲しかできなかったため上記の点数でした。
やりたかった解法は以下のとおり。
問題の解釈
問題を良く読むと、縦か横のひと繋がりの道を「通り」としたとき、
「全ての道路を見渡す」は「全ての通りに最低1回は到達する」と同値であることがわかる。
また、それぞれの通りには必ず交差点で到達するので、経路を考えるときには交差点のみを考えれば良い。
つまり、「どの順番で通りを巡回するか、それぞれの通りにおいてどの交差点を経由するか」を定める問題と解釈しなおすことができる。
解法
前者の「どの順番で通りを巡回するか」は巡回セールスマン問題の2-optのような解法で焼きなましていけば良さそう。
後者の「それぞれの通りにおいてどの交差点を経由するか」は真面目にはさまざまな解法がありそうだが、シンプルにはスタートから
順に交差点を定めていき、前の交差点から最も近い交差点を選んでいけば良い。
交差点間の距離
上記の解法で経路の長さを求めるには各交差点間の距離が必要になる。
テストデータの交差点数は最大で1000個くらいあるように思えた(もうちょっと少ないかもしれない)
ここで、ワーシャルフロイド法を使うとO(交差点数の3乗)のため交差点数=1000だと間に合わない。
しかし、各点を始点とするダイクストラ法を行えば良い。ダイクストラ1回の計算量は O((辺の数+交差点数) log 交差点数)であり、辺の数<交差点数 x 4 なので十分間に合う。
本番ではここが思いつかず、どうにもそこから先に進めなかった。
スコア
前処理で交差点間の距離の計算を行っておけば、2-optで差分計算をせずに素朴に計算しても3秒で150万回くらいは試行できた。温度を適当に調整すると20.8M, optunaでもうちょっと調整すると21.5Mで、15-20位前後のスコアになった。 https://atcoder.jp/contests/ahc005/submissions/24899313